Neural Discrete Representation Learning
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.neurips.cc
수식이 깨져서 보일 경우 URL주소에서 /m 부분을 삭제해주세요. 모바일 환경에서 깨집니다.
Abstract
지도작업 없이 유용한 표현을 학습하는 것은 매우 중요하다. 우리는 이산 표현을 학습하는 간단하지만 강력한 생성모델을 제안한다. VAE와 다른 Vector Quantised-Variational AutoEncoder (VQ-VAE)는 인코더에서 이산표현을 출력하고 학습가능한 prior을 가진다. 이산 표현을 학습하기 위해 vector quantisation(VQ)를 도입하였고 이는 "posterior collapse"를 방지한다. 비지도 학습을 이용한 표현 학습에서 VQ와 autoregressive prior의 조합은 매우 고품질의 이미지, 비디오, 음성을 생성할 수 있다.
*posterior collapse : 이미지를 생성하는 VAE의 경우 latent vector z에 의해 이미지를 생성하게 되는데 sequential data를 생성하는 autoregressive model의 경우 이미지를 생성하면서 latent vector z를 무시하게 되는 경향이 발생한다. 특히 긴 sequence일수록 무시되는 경향이 더욱 심해지고 이를 posterior collapse라고 한다.
VQ-VAE

Discrete Latent variables
우리는 D차원의 latent embedding vector \(e_i\)와 K크기의 discrete latent space를 가지는 latent embedding space \(e\in R^{K\times D}\)를 정의한다. 이는 K개의 embedding vectors \(e_i\in R^D, i\in 1,2,...,.K\)가 있다는 것이다.Fig1과 같이 모델은 x를 입력받아 인코더를 통해 \(z_e(x)\)를 출력한다. 이산 변수 z는 (1)에서 표현된 shared embedding space e 에 의해 nearest neighbour look-up으로 계산된다. 디코더로 입력되는 input은 (2)에 의해 상응하는 embedding vector \(e_k\)가 된다.

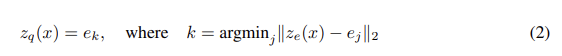
인코더로부터 출력된 \(z_e(x)\)는 code-book에 해당하는 embedding space중 가장 가까운 인덱스(ex. 유클리디언 거리)로 코딩되고 이를 이용해 디코더는 원본을 복원하게 된다.
(3)은 모델 훈련에 사용된 모든 손실함수에 대한 수식이다. 이는 3개의 항으로 구성되어 있으며 이는 각 reconstruction loss, VQ objective, commitment loss이다.
reconstruction loss는 인코더와 디코더간에 원본을 복원하기 위해 사용되는 손실함수이다.
\(z_e(x) \to z_q(x)\)에서 맵핑을 위해 사용된 embeddings \(e_i\)는 reconstruction loss로부터 손실값을 전달받지 못한다. 그렇기 때문에 embedding space를 학습하기 위해 우리는 가장 간단한 dictionary embedding algorithms인 Vector Quantisation을 사용하였다. VQ objective는 \(l_2\) error을 통해 embedding vector \(e_i\)를 encoder output \(z_e(x)\)의 방향으로 이동시킨다(Fig1의 우측).
마지막으로 embedding space는 차원이 존재하지 않기 때문에 embeddings \(e_i\)가 encoder만큼 빠르게 훈련되지 않으면 값이 매우 커질 수 있다.encoder의 값과 embedding이 가까운 값을 출력하고 제약을 걸어주기 위한 항으로 commitment loss를 추가하였다.

Experiments and Results
1. Images
이미지는 대부분의 픽셀들이 노이즈이거나 연관관계를 가지고 있어 중복된 정보를 포함하고 있다. 때문에 픽셀수준에서 모델을 학습하는 것은 매우 낭비적이다. 우리는 128x128x3 크기의 이미지를 (K=512)인 32x32x1의 공간으로 압축시킨 후 이를 복구하도록 학습하였다. 우리는 PixelCNN을 이용한 z의 잠재공간에서 학습을 진행하였고 이는 매우 빠를뿐만 아니라 이미지의 전역 정보를 포착할 수 있다.

매우 저차원으로 압축한 것을 고려하면 복원된 이미지는 원본에 비해 조금 blurrier할 뿐이다.
특별한 결과 내용은 없어서 자세한 결과는 원문을 참고하길 바란다..
https://colab.research.google.com/github/zalandoresearch/pytorch-vq-vae/blob/master/vq-vae.ipynb
vq-vae.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
필자도 잘 이해가 되질 않아서 정리가 어려운데 위 코드를 참고하면 이해가 좀 쉬울 것 같다.
Code Review
Fig1의 flow를 따라서 데이터가 입력되고 훈련되는 과정을 직접 보도록 하겠다.
위 코랩의 코드를 기반으로 실습했으며 지수평균이동을 사용하는 vectorquantizerEMA는 코드에서 제외하였다.

위 코랩의 다이어그램을 살펴보면 모델의 구조는 위 그림과 같다고 한다.
다이어그램에서는 (B, 3, 32, 32)크기의 이미지를 이용하였지만 본 실습에서는 (B=16, 3, 128, 128)의 예시 데이터를 사용할 것이다.
변수 선언부터 보면서 어디에 사용되는 변수인지 확인해보면
batch_size = 256 # 배치사이즈
num_training_updates = 15000 # epochs (훈련 횟수)
num_hiddens = 128 # 인코더의 출력 채널
num_residual_hiddens = 32 # Residual Layer의 hidden_dim, SE-Net처럼 채널을 축소,확장하기 위한 차원
num_residual_layers = 2 # Residual Layer 갯수
embedding_dim = 64 # Code Book의 인덱스 갯수
num_embeddings = 512 # Code Book의 각 인덱스 당 차원
commitment_cost = 0.25 # Commitment_loss 계수
Model
class Model(nn.Module):
def __init__(self, num_hiddens, num_residual_layers, num_residual_hiddens,
num_embeddings, embedding_dim, commitment_cost, decay=0):
super(Model, self).__init__()
self._encoder = Encoder(3, num_hiddens,
num_residual_layers,
num_residual_hiddens)
self._pre_vq_conv = nn.Conv2d(in_channels=num_hiddens,
out_channels=embedding_dim,
kernel_size=1,
stride=1)
self._vq_vae = VectorQuantizer(num_embeddings, embedding_dim,
commitment_cost)
self._decoder = Decoder(embedding_dim,
num_hiddens,
num_residual_layers,
num_residual_hiddens)
def forward(self, x):
z = self._encoder(x)
z = self._pre_vq_conv(z)
loss, quantized, perplexity, _ = self._vq_vae(z)
x_recon = self._decoder(quantized)
return loss, x_recon, perplexity
모델의 구조를 먼저 살펴보도록 하겠다.
모델은 1) 인코더 2) conv 맵핑 3) vq_vae 4) 디코더 로 이루어져 있다.
Encoder
class Encoder(nn.Module):
def __init__(self, in_channels, num_hiddens, num_residual_layers, num_residual_hiddens):
super(Encoder, self).__init__()
self._conv_1 = nn.Conv2d(in_channels=in_channels,
out_channels=num_hiddens // 2,
kernel_size=4,
stride=2, padding=1)
self._conv_2 = nn.Conv2d(in_channels=num_hiddens // 2,
out_channels=num_hiddens,
kernel_size=4,
stride=2, padding=1)
self._conv_3 = nn.Conv2d(in_channels=num_hiddens,
out_channels=num_hiddens,
kernel_size=3,
stride=1, padding=1)
self._residual_stack = ResidualStack(in_channels=num_hiddens,
num_hiddens=num_hiddens,
num_residual_layers=num_residual_layers,
num_residual_hiddens=num_residual_hiddens)
def forward(self, inputs):
x = self._conv_1(inputs)
x = F.relu(x)
x = self._conv_2(x)
x = F.relu(x)
x = self._conv_3(x)
return self._residual_stack(x)
Resnet을 이용할줄 알았는데 그냥 간단한 conv layer들로 구성하였고 마지막은 Residual connection을 통해 feature 정보를 주입시켜 주었다. ResidualStack 클래스는 별 내용 없으니 궁금하면 코랩 참조 바람
임의의 데이터를 인코더만 통과시켜보면

인코더에 풀링레이어는 없지만 stride=2인 conv layer가 2개 존재하기 때문에 H, W가 줄어들고 미리 정의된 num_hiddens=128 차원으로 채널이 확장된다.
Pre_Vq_Conv
pre_vq_conv는 Model 클래스에 정의되어 있는데 인코더에서 임베딩된 num_hiddens을 입력받아 embedding_dim채널로 축소시킨다. (128 -> 64)

vq_vae
class VectorQuantizer(nn.Module):
def __init__(self, num_embeddings, embedding_dim, commitment_cost):
super(VectorQuantizer, self).__init__()
self._embedding_dim = embedding_dim
self._num_embeddings = num_embeddings
self._embedding = nn.Embedding(self._num_embeddings, self._embedding_dim)
self._embedding.weight.data.uniform_(-1 / self._num_embeddings, 1 / self._num_embeddings)
self._commitment_cost = commitment_cost
def forward(self, inputs):
# convert inputs from BCHW -> BHWC
inputs = inputs.permute(0, 2, 3, 1).contiguous()
input_shape = inputs.shape
# Flatten input
flat_input = inputs.view(-1, self._embedding_dim)
# Calculate distances
distances = (torch.sum(flat_input ** 2, dim=1, keepdim=True)
+ torch.sum(self._embedding.weight ** 2, dim=1)
- 2 * torch.matmul(flat_input, self._embedding.weight.t()))
# Encoding
encoding_indices = torch.argmin(distances, dim=1).unsqueeze(1)
encodings = torch.zeros(encoding_indices.shape[0], self._num_embeddings, device=inputs.device)
encodings.scatter_(1, encoding_indices, 1)
# Quantize and unflatten
quantized = torch.matmul(encodings, self._embedding.weight).view(input_shape)
# Loss
e_latent_loss = F.mse_loss(quantized.detach(), inputs)
q_latent_loss = F.mse_loss(quantized, inputs.detach())
loss = q_latent_loss + self._commitment_cost * e_latent_loss
quantized = inputs + (quantized - inputs).detach()
avg_probs = torch.mean(encodings, dim=0)
perplexity = torch.exp(-torch.sum(avg_probs * torch.log(avg_probs + 1e-10)))
# convert quantized from BHWC -> BCHW
return loss, quantized.permute(0, 3, 1, 2).contiguous(), perplexity, encodings
이 코드가 젤 어렵게 느껴졌다. 위 코드에서 forwad문의 주석을 따라가며 벡터의 흐름을 살펴보겠다.
가장먼저 inputs은 pre_vq_conv에서 얻은 (16, 64, 32, 32)의 데이터가 입력된다.
# convert inputs from BCHW -> BHWC
inputs = inputs.permute(0, 2, 3, 1).contiguous()
input_shape = inputs.shape
# Flatten input
flat_input = inputs.view(-1, self._embedding_dim)
inputs을 BCHW -> BHWC의 형태로 바꾸고 BHW를 펼쳐준다. 근데 왜 배치차원을 펼치는지는 잘 모르겠다. 보통 배치가 섞이지 않게 하기 위해 배치 차원은 내버려 둬야 하지 않나..?(신명호는 내버려두라고)
어쨌든 하라는대로 하면 다음과 같은 결과가 나온다.

# Calculate distances
distances = (torch.sum(flat_input ** 2, dim=1, keepdim=True)
+ torch.sum(self._embedding.weight ** 2, dim=1)
- 2 * torch.matmul(flat_input, self._embedding.weight.t()))코드북과 가장 가까운 거리에 있는 인덱스를 찾기 위해 거리를 계산한다.

flat_input을 제곱한 후 64채널의 합을 구한다.
vq_vqe의 코드북의 weight을 제곱한 후 합을 구한다.

둘을 더하면 (16384, 512)의 벡터로 변환된다.
이후 두 벡터들의 내적을 구한 후 2를 곱한 값을 빼면

똑같은 차원인 (16384, 512)의 벡터를 반환한다.
이 코드는 주로 임베딩된 표현(embedded representation)간의 유사도를 계산하는 데 사용된다고 한다.
여기까지 정리해보면 16384 벡터에 대해 코드북의 512 인덱스들간에 유사도 행렬을 구하였다.
# Encoding
encoding_indices = torch.argmin(distances, dim=1).unsqueeze(1)
encodings = torch.zeros(encoding_indices.shape[0], self._num_embeddings, device=inputs.device)
encodings.scatter_(1, encoding_indices, 1)
16384 벡터들의 인덱스 값 512 중 가장 높은 유사도를 가진 값을 구하고 해당 하는 인덱스에 1을 집어넣는 희소 행렬을 만든다.

이제 마지막 코드를 살펴보겠다.
# Quantize and unflatten
quantized = torch.matmul(encodings, self._embedding.weight).view(input_shape)
# Loss
e_latent_loss = F.mse_loss(quantized.detach(), inputs)
q_latent_loss = F.mse_loss(quantized, inputs.detach())
loss = q_latent_loss + self._commitment_cost * e_latent_loss
quantized = inputs + (quantized - inputs).detach()
avg_probs = torch.mean(encodings, dim=0)
perplexity = torch.exp(-torch.sum(avg_probs * torch.log(avg_probs + 1e-10)))
# convert quantized from BHWC -> BCHW
return loss, quantized.permute(0, 3, 1, 2).contiguous(), perplexity, encodings현재 encodings shape = (16384, 512), self._embedding.weight shape = (512, 64) 이다.
두 행렬을 내적하면 (16384, 64)로 변환되고 이를 다시 input_shape이었던 (16, 32, 32, 64)의 벡터로 변환한다.
마지막은 전지전능한 GPT의 힘을 빌려 설명해보면
여기서 각 부분을 살펴보겠습니다:
- quantized: 양자화된 임베딩을 다시 펼친 다음 원래 입력의 모양으로 되돌립니다.
- e_latent_loss 및 q_latent_loss: 임베딩의 잠재 손실을 계산합니다. e_latent_loss는 원본 입력과 양자화된 임베딩의 잠재적인 잃어버린 정보를 나타내며, q_latent_loss는 원본 입력과 양자화된 임베딩 간의 차이를 나타냅니다. 이러한 손실은 평균 제곱 오차(MSE)를 사용하여 계산됩니다.
- loss: 전체 손실은 양자화된 임베딩의 손실과 잠재적인 잃어버린 정보에 대한 페널티를 나타내는 'commitment cost'의 곱으로 정의됩니다.
- quantized: 원본 입력과 양자화된 임베딩 간의 차이를 보상하기 위해 양자화된 임베딩을 수정합니다.
- avg_probs 및 perplexity: 양자화된 벡터의 확률 분포를 사용하여 평균 엔트로피를 계산하고, 이를 통해 모델의 복잡성을 나타내는 'perplexity'를 계산합니다.
- 마지막으로, 양자화된 표현을 원하는 형식으로 변환하여 반환합니다.
코드 중간중간 detach를 활용하여 목표한 네트워크에만 가중치가 역전파 될 수 있도록 하는것이 눈여겨볼 점이다.
Decoder
class Decoder(nn.Module):
def __init__(self, in_channels, num_hiddens, num_residual_layers, num_residual_hiddens):
super(Decoder, self).__init__()
self._conv_1 = nn.Conv2d(in_channels=in_channels,
out_channels=num_hiddens,
kernel_size=3,
stride=1, padding=1)
self._residual_stack = ResidualStack(in_channels=num_hiddens,
num_hiddens=num_hiddens,
num_residual_layers=num_residual_layers,
num_residual_hiddens=num_residual_hiddens)
self._conv_trans_1 = nn.ConvTranspose2d(in_channels=num_hiddens,
out_channels=num_hiddens // 2,
kernel_size=4,
stride=2, padding=1)
self._conv_trans_2 = nn.ConvTranspose2d(in_channels=num_hiddens // 2,
out_channels=3,
kernel_size=4,
stride=2, padding=1)
def forward(self, inputs):
x = self._conv_1(inputs)
x = self._residual_stack(x)
x = self._conv_trans_1(x)
x = F.relu(x)
return self._conv_trans_2(x)
디코더는 인코더와 유사하지만 이미지를 복원하기 위해 ConvTransposed2D를 사용하였다.

vq_vae에서 구한 quantized를 디코더에 입력시키면 입력 이미지의 차원과 똑같은 출력을 내며 이미지를 복원한다.
마치며
보통 VAE에서는 학습가능한 latent space를 이용하여 모델의 훈련 내내 이미지셋의 통계값에 근접하도록 훈련되게 된다. 전혀 새로운 방법인 vector quantization을 보며 도대체 어떻게 학습이 되는것인가 했는데 여기서는 사전 정의된 코드북을 이용하여 훈련내내 코드북은 업데이트 되지 않는다고 한다. 코드를 뜯어봐도 사실 쉽게 이해가 되지 않긴 한다. VAE와 달리 이미지의 통계값을 이용하지 않으니 image generation보다는 image super resolution이나 segmentation에 사용해보면 좋을 것 같다는 생각이 든다.
'논문 리뷰' 카테고리의 다른 글
| Vision transformers need registers 리뷰 (0) | 2024.04.18 |
|---|---|
| IBOT : IMAGE BERT PRE-TRAINING WITH ONLINETOKENIZER 리뷰 (0) | 2024.04.17 |
| Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction 리뷰 (0) | 2024.04.15 |
| DINOv2: Learning Robust Visual Features without Supervision 리뷰 (0) | 2024.04.11 |
| Bootstrap Your Own Latent A New Approach to Self-Supervised Learning 리뷰 (0) | 2024.04.09 |



