Vision Transformers Need Registers
Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm toke
arxiv.org
DINOv2 깃허브를 보다가 basic DINO와 register 이라고 적혀있는것도 있길래 뭐지? 하고 살펴보다 발견한 논문
Abstract
트랜스포머는 시각적 표현학습을 위한 강력한 도구로 급부상하고있다. 우리는 supervised, self-supervised된 ViT의 feature map에서 artifact들을 식별하고 특징화 한다. 이 아티팩트들은 high-norm에 해당하는데 이는 정보가 적은 배경 이미지에서 발생한다. 우리는 ViT의 입력시퀀스에 추가적인 토큰을 넣어 dense visual prediction task에서 새로운 기록을 달성했다. 또한 downstream visual processing에서 더욱 부드러운 시각화 feature map을 제공한다.

Introduction
이미지를 임베딩하여 특정 task를 위한 특징을 생성하는것은 비전에서 당연시 되어가고 있다. 오늘날 이는 매우 많은 양의 데이터로 학습된 모델을 이용하며 다양한 방법들에 가능성을 제공하고 있다. 또한 자기주도학습으로 훈련된 ViT구조의 모델은 downstream에서 뛰어난 예측 능력으로 주목받고 있다(DINO).
DINOv2는 DINO와 다르게 동작하는것으로 보여지는데, feature map을 생성하는 과정에서 DINOv2는 DINO에서는 보여지지 않았던 아티팩트들이 두드러지게 노출되는것이 확인된다. Fig2에서 확인할 수 있듯이, 이러한 아티팩트들은 다른 ViT기반의 모델들에서도 나타나며 DINO에서만 예외적으로 나타나지 않는것을 볼 수 있다.
본 연구에서는, 이 아티팩트들에 대한 이해와 이를 감지 하기 위한 기술을 개발할것이다. 아티팩트는 전체 시퀀스의 2%에 해당하지만 출력의 10배 크기의 노름인것을 관찰할 수 있었다. 이러한 이상치 토큰은 이미지 내에 원래 위치에서의 정보나 픽셀에 대한 정보를 매우 적게 담고 있었고 추론과정에서 해당 정보들을 버린다는것을 시사한다. 반면에 이상치 토큰을 이용한 분류 학습시 다른 패치들보다 높은 정확도를 얻을 수 있었으며 이 토큰들은 이미지의 전역 정보를 포함한다는 것을 시사한다.
이는 제한된 토큰만을 이용하는 트랜스포머 모델의 내부 메커니즘과 연관되어 있으며 이를 검증하기 위해 추가적인 토큰인 register 토큰을 추가하였을때 이상치 토큰은 시퀀스에서 소멸되었으며 feature map 역시 매우 부드러워진 것을 확인할 수 있었다.
Problem Fomulation
1. Artifacts are high-norm outlier tokens
- 우리는 모델의 출력에서 나오는 토큰 임베딩의 노름이 'artifact'패치와 다른 패치들간에 중요한 차이인것을 확인했다. Fig3의 왼쪽을 보면 추론이미지에 대한 artifact 패치들이 다른 노름에비해 매우 높다. 소규모 데이터셋에 대한 norm distribution을 그려보았는데(오른쪽), high-norm이라고 간주되는 150이상의 토큰들과 다른 토큰들에 대해 연구할 것이다.
2. Outliers appear during the training of large models
- 우리는 DINOv2를 훈련시키면서 이상치 토큰이 등장하는 추가적인 조건에 대해 관찰하였다. 40-Layer ViT의 15번째 layer에서 다른 패치들과 구별되며 훈련의 1/3이 경과한 시점부터 관측 가능한 것이였다. 또한 여러 모델 사이즈(Tiny, Small, Base, Large, Huge, Giant) 중 크기가 큰 3개의 모델에서만 관측 가능했다(Large, Huge, Giant).
3. High-norm tokens appear where patch information is redundant
- 이를 검증하기 위해 우리는 Patch Embedding Layer(트랜스포머 입력 부분)이후에 획득한 high-norm 토큰과 인접한 4개의 patch 들의 코사인 유사도를 측정하였다. Fig 5a는 이를 그린것인데 high-norm토큰들은 이웃한 것들과 매우 유사하게 관찰되었다(normal token이 높을 때 artifact도 높아지는것을 말하는건가?). 이는 토큰들이 중복된 정보를 포함하기 때문에 모델이 이미지의 표현을 해치지 않으면서 토큰 정보들을 버릴 수 있다는 것을 시사한다. 이러한 관찰점은 Fig2에서 균일한 배경영역에서만 관찰되는 것과 일치한다.(추론 이미지가 달라져도 각 모델에서 등장하는 이상치 토큰들이 균일한 영역에 분포되어 있다)
4. High-norm tokens hold little local information
- 우리는 Position prediction, pixel reconstruction을 통해 토큰의 성격을 조사할 것이다. 패치 임베딩 위에 선형 계층을 놓아 모델의 성능을 비교한다. 이는 high-norm이 다른 토큰에 비해 다른 정보를 포함하는지를 알 수 있다.
- Position Prediction : Fig5 b를 보면, high-norm은 다른 토큰에 비해 매우 낮은 정확도를 갖기 때문에 위치 정보가 적다는 것을 알 수 있다.
- Pixel Reconstruction : normal에 비해 낮은 수치를 보이기 때문에 이 역시 이미지 픽셀 정보가 적다는 것을 내포한다.
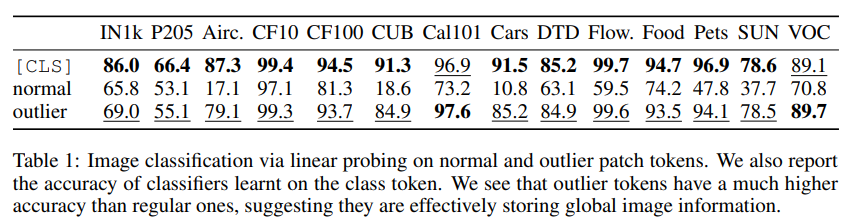
5. Artifacts hold global information
- 우리는 high-norm 토큰이 이미지의 global information을 얼마나 내재하고 있는지에 대해 조사하였다. 패치 임베딩에서 high-norm, normal 중 무작위로 추출한 토큰을 image representatino으로 간주하여 logistic regression을 훈련시킨 후 accuracy를 측정하였다. Table 1 에서와 같이 high-norm이 다른 토큰에 비해 높은 정확도를 가지고 이는 더 많은 global information을 가진 다는 것을 시사한다.
우리는 간단한 방법을 통해 이를 방지할 것이다. 우리는 embedding layer 이후 cls token과 같은 형식으로 register 토큰을 추가할 것이고 이는 모델의 마지막 부분에서 제거될 것이며 훈련과 추론에서는 보통과 같이 cls 토큰만을 이용한다.
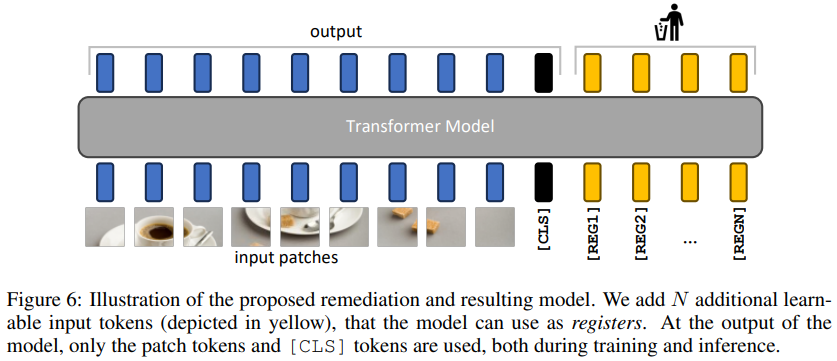
흐음.. Register을 추가하는건 알겠는데 단순히 토큰만 추가해서 high-norm 토큰들을 없앨 수 있다는것인가.. ?
Experiments and Results
자세한 실험결과는 논문을 참고하길 바라고 필자가 관심있게 본 내용만을 정리하였다.
Number of register tokens
DINOv2 VIT-L/14 model에 대해 0, 1, 2, 4, 8, 16개의 register토큰을 추가하여 갯수에 따른 성능을 비교하였다. 시각화 자료에서는 하나의 토큰추가만으로도 부드러운 feature map을 획득하였다. 또한 아래의 downstream task 그래프를 보면 1개의 토큰만을 추가해도 모든 task에서 성능이 향상되었고 특히 imagenet은 토큰이 증가할수록 정확도도 같이 올랐다. 우리는 모든 실험에서 4개의 reg 토큰을 사용하였다.

Qualitative evaluation of registers
마지막으로 우리는 reg 토큰이 모두 비슷한 attention map을 갖는지 확인하였다. Fig 9을 보면 reg 토큰은 모두 일치하지 않는 동작을 보이고 서로 다른 객체에 attention하는 경향을 보이기도 한다. 우리는 이러한 동작을 강제하지 않았지만 모델의 훈련과정에서 자연스럽게 학습된 것으로 추측한다.

'논문 리뷰' 카테고리의 다른 글
| Segment Anything 리뷰 (0) | 2024.04.22 |
|---|---|
| Segmenter: Transformer for Semantic Segmentation 리뷰 (0) | 2024.04.19 |
| IBOT : IMAGE BERT PRE-TRAINING WITH ONLINETOKENIZER 리뷰 (0) | 2024.04.17 |
| Neural discrete representation learning(VQ-VAE) 리뷰 + 코드 (0) | 2024.04.15 |
| Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction 리뷰 (0) | 2024.04.15 |



