CVPR 2022 Open Access Repository
Masked-Attention Mask Transformer for Universal Image Segmentation Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1290-1
openaccess.thecvf.com
이전 논문 리뷰하는데 mask decoder, mask transformer가 자주 등장하길래 한번 살펴보았다.
Abstract
segmentation은 panoptic, instance semantic 등 여러가지의 task로 나누어져 있고 모델들은 각각의 task에 대해서만 초점을 맞추고 있다. Masked-attention Mask Transformer(Mask2Former)은 모든 segmentation에 적용될 수 있는 새로운 구조의 모델이다. 이 모델은 예측된 마스크 영역 내에서 cross-attention을 수행하여 지역적 특성을 추출하는 masked attention이 핵심이다.
Transformer decoder with masked attention
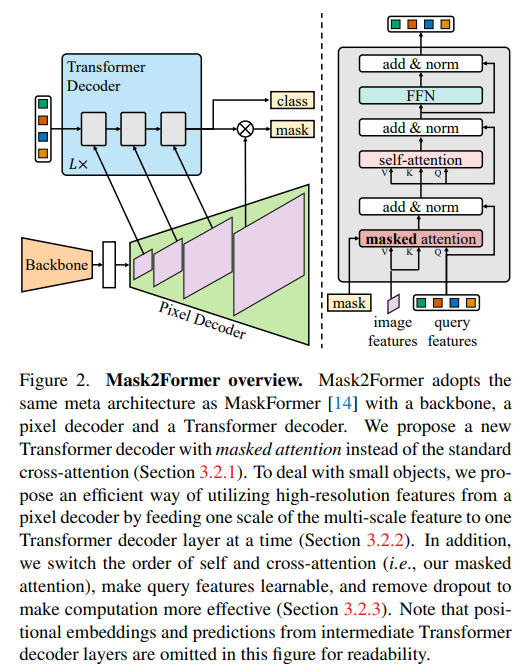
Mask2Former은 MaskFormer를 backbone으로 채택하였으며 변형된 transformer decoder을 적용하였다. 디코더는 전체 feature map의 attention score을 계산하지 않고 각 쿼리에서 예측된 마스크들에 대해 cross-attention을 적용하여 지역적인 특징을 추출한다. 작은 객체를 처리하기 위해서는 피라미드 형태의 디코더로 여러 크기의 feature map을 전달하는 전략을 채택하였다.
Masked attention
최근 연구들은 image segmentation에서 전역정보가 중요하지만 이는 cross-attention의 수렴속도를 지연시켜 모델의 훈련을 어렵게 한다고 시사한다. 하지만 우리는 쿼리만으로도 local feature를 학습 가능하고 self-attention을 통해 전역 정보를 수집할 수 있다고 가정한다. Masked attention의 수식은 다음과 같다.

\(l\) : layer index
\(X_l\in R^{N\times C}\) : \(l^{th}\)번째 layer의 \(N C-dim\) query feature
\(Q_l\) = \(f_Q(X_{l-1})\in R^{N\times C}\)
\(M_{l-1}\in \{0,1\}^{N\times H_lW_l}\) : (l-1) decoder layer에서의 mask prediction에 대한 이진 출력 (threshold = 0.5)
(기존 트랜스포머의 QKV연산에 단계적으로 mask prediction의 값들이 더해지는 형태인 듯 하다. 근데 query features는 여러개가 존재하는데 이게 pixel decoder의 단계적인 쿼리를 뜻하는건지는 잘 모르겠다.)
High-resolution features
높은화소에서 획득한 feature은 작은 객체에 대한 성능을 향상시키지만 게산비용 또한 요구된다. 우리는 저, 고화질의 특징을 모두 획득할 수 있는 feature 피라미드을 적용하였고 각 scale에서의 feature는 각 decoder layer로 입력된다. pixel decoder로부터 원본 이미지의 1/32, 1/16, 1/8 크기의 특징이 제공되며 sinusoidal positional embedding과 learnable scale-level embedding이 더해진다. Fig2의 좌측에 보이는 3-layer의 디코더는 L번 반복된다.
Optimization improvements
우리는 기존 트랜스포머의 디코더에 다음과 같은 변형을 가했다. 1) self-attention과 cross-attention의 수행 순서를 변경하였다. 2) 학습 가능한 query feature을 사용하였고 이는 mask를 예측하기전에 supervised 된다(무슨말인지 잘 모르겠다 애초에 q,k,v모두 학습가능한 벡터 아니였나..? 기존의 트랜스포머는 query가 zero-initialized된점과 다르다고 한다, NLP의 트랜스포머는 이해도가 낮아서 패스) 3) dropout은 필수적이지 않고 심지어 성능을 저하시켰기 때문에 디코더에서 모두 제거하였다.
Improving training efficiency
Mask2Former은 고해상도의 마스크 예측때문에 32G 메모리의 GPU에서 하나의 이미지만 학습이 가능하다. 우리는 PointRend, Implicit PointRend에서 영감을 받아 K개(12544, 122x122 points)의 랜덤 포인트에서 mask loss를 계산한다.
이후 실험 결과와 ablation study는 논문을 참조하길 바람
'논문 리뷰' 카테고리의 다른 글
| The fully convolutional transformer for medical image segmentation 리뷰 (0) | 2024.04.23 |
|---|---|
| Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation 리뷰 (0) | 2024.04.22 |
| Segment Anything 리뷰 (0) | 2024.04.22 |
| Segmenter: Transformer for Semantic Segmentation 리뷰 (0) | 2024.04.19 |
| Vision transformers need registers 리뷰 (0) | 2024.04.18 |



