LLM만들기 (1)편에서는 AI-hub의 공공 데이터셋을 불러와 하나의 파일로 저장을 완료하였습니다.
(2) 편에서는 fine-tuning 하고자 하는 모델을 직접 불러와보도록 하겠습니다.
그 전에 먼저 어떤 LLM들이 존재하는지 알아보도록 하겠습니다.
최근 자연어 처리분야에서 LLM이라고 불리는 모델들은 대체로 Transformer구조를 기반으로 한 모델들입니다.
최근 없어서는 안될 요소가 된 Chat-GPT, BERT, RoBERTa, DistillBERT 등 모델의 크기나 구조에따라 매우 다양한 버전이 존재하지만 대부분 GPT/BERT를 기반으로 파생된 모델들입니다.
그럼 GPT와 BERT는 뭐가 다른것이냐? 이는 Transformer의 구조에서 인코더를 사용했느냐, 디코더를 사용했느냐에 따라 달라지게 됩니다.

트랜스포머는 위 그림과 같이 인코더와 디코더가 합쳐진 구조로, 인코더에서는 문장의 의미를 압축하고, 디코더에서는 압축된 의미를 이용해 다시 문장을 생성하거나 문장 사이 알맞은 단어를 끼워 넣도록 학습됩니다.
이러한 학습 과정이 있기 때문에 인코더의 구조만을 이용한 BERT(Bidirectional Encoder Representations from Transformers
), 디코더의 구조만을 이용한 GPT(Generative Pre-trained Transformer)로 나뉘게 됩니다. 그렇기 때문에 챗-GPT는 사용자의 질문에 맞는 문장을 생성하는 것이죠.
우리가 해야될 작업은 한국어(원문)를 입력받아 영어(번역문)을 생성
하는 것이기 때문에 GPT 모델을 이용하도록 하겠습니다.
현재 OpenAI에서는 GPT-4까지 공개하였으며 GPT-5를 출시하기 위해 준비중이라고 합니다. 하지만 GPT-3부터 모델의 악용을 방지하기 위해 pre-trained weight를 공개하지 않았기 때문에 우리는 GPT-2의 가중치를 불러오도록 하겠습니다.
import pandas as pd
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
print(tokenizer)
print(model)
huggingface에 등록되어 있는 GPT-2의 모델 가중치와 토크나이저를 불러왔습니다.
토크나이저는 인간의 언어를 컴퓨터 언어로 "토큰화" 시켜주기 위한 것으로 데이터의 전처리를 위한 도구입니다.
위 예시와 같이 주어, 목적어, 마침표와 같은 모든 단어의 빈도수와 형태에 따라 특정한 숫자로 "토큰화" 됩니다.
만약 위와 같이 "오늘" = 56 으로 토큰이 지정되었다면 "오늘오늘오늘"=[56, 56, 56]과 같이 토큰화 됩니다.
그럼 모든 단어를 토큰화 하는것일까요?
모든 단어를 토큰화 하기엔 한글의 단어수는 약 110만개라고 하니 이를 모두 숫자로 표현하기엔 매우 벅찰것입니다. 그래서 LLM들은 단어의 빈도수가 많은순으로 그 수를 제한하기 위해 vocab_size라는 것을 만들었습니다.
print(tokenizer)로 출력한 토크나이저의 파라미터를 보면 gpt2의 vocal_size는 50257로 제한되어있습니다. 만약 50257 단어에 속하지 않는 "뀷뜕" 이라는 단어가 들어오게 된다면 이는 "Unknown" 을 뜻하는 약속된 토큰으로 바뀔 것입니다. 위에서는 special_toknes에 'unk_token' 으로 표시되어 있습니다.
(최근 Chat-GPT가 "햔뀪윈뫈 뾸쓔있뉸 뤼쀼읩늬땨" 와 같은 말들도 알아듣는다고 하는데 기술력이 어느정도인건지..)
이번엔 print(model)을 해보겠습니다.
가장 먼저 보이는 layer는 wte, wpe 라는 임베딩 계층으로 이들은 각 Word Token Embedding, Word Positional Embedding의 약자입니다.
Word Token Embedding은 50257개의 단어로 토큰화된 단어들을 768차원으로 임베딩 하기 위한것이라면 wpe는 무엇일까요?
print(tokenizer)의 사진을 다시 확인해보면 model_max_length=1024 를 확인할 수 있습니다. 이는 문장의 최대 길이를 의미합니다. 자연어는 단어의 위치에 따라 다른 의미를 지닐 수 있기 때문에 단어의 위치 정보를 모델에 학습시키기 위한 것입니다. (자세한 내용은 위치 임베딩, 위치 인코딩 등을 검색해보시기 바랍니다.)
wte wpe를 통해 768차원으로 임베딩 된 벡터들은 다음과 같이 서로 더해진 뒤 모델에 다음 계층으로 입력됩니다.
-> input = wte + wpe
아래는 gpt2의 원문 코드입니다. (https://github.com/openai/gpt-2/blob/master/src/model.py)
wte+wpe로 이루어진 768차원의 벡터는 이후 12개의 GPT-Block를 통해 학습이 진행되게 됩니다. GPT-Block를 통해 모델이 학습된 후 다시 특정 문자들을 생성 하기 위해서 lm_head라는 계층에서 768차원 -> 50257차원(tokenizer-vocab_size)로 변환시킨 벡터를 출력합니다.
모델을 성공적으로 불러왔다면, 훈련이 진행되기전 한국어와 영어를 입력했을때 GPT-2는 어떤 출력을 내게 되는지 보겠습니다. 그 전에, 우리가 가진 데이터셋의 원문과 번역문의 최대 길이는 얼마나 되는지 확인해보겠습니다.
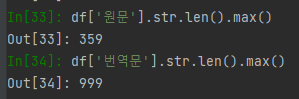
다행히 tokenizer의 max_length인 1024를 넘지 않으니 하이퍼 파라미터를 수정하지 않아도 되겠습니다.
(1) 장에서 저장한 데이터셋을 불러와 GPT에 입력 후 텍스트를 생성해보도록 하겠습니다.
import pandas as pd
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.eval()
df = pd.read_csv('translation_with_llm/dataset.csv')
inputs = df.sample(1)
kor_inputs = "translate Korean to English : " + str(inputs['ko'].item())
eng_inputs = "translate English to Korean : " + str(inputs['en'].item())
kor_encode = tokenizer.encode(kor_inputs, max_length=1024, truncation=True, return_tensors='pt')
eng_encode = tokenizer.encode(eng_inputs, max_length=1024, truncation=True, return_tensors='pt')
kor_outputs = model.generate(kor_encode, max_length=128, pad_token_id=tokenizer.eos_token_id)
eng_outputs = model.generate(eng_encode, max_length=128, pad_token_id=tokenizer.eos_token_id)
kor_decode = tokenizer.batch_decode(kor_outputs, skip_special_tokens=True)
eng_decode = tokenizer.batch_decode(eng_outputs, skip_special_tokens=True)
print(f'한국어 원문 : {kor_inputs}, \n한국어 출력 : {kor_decode}')
print(f'\n영어 원문 : {eng_inputs}, \n영어 출력 : {eng_decode}')
원문과 번역문에 각각에 대한 작업을 의미하는 translate a to b 라는 prompt를 추가하여 모델에 입력하였습니다. 이를 통해 모델은 어떤 작업을 시행해야 하는지 간접적으로 파악할 수 있습니다.
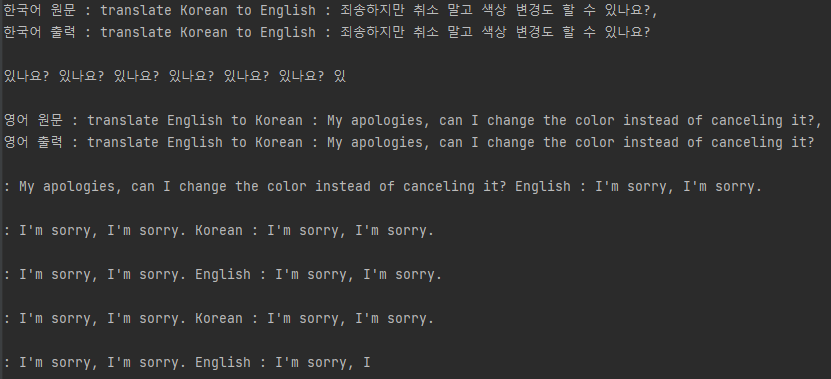
챗-GPT의 고급스러운 답변만을 보다가 우리의 GPT-2가 내놓은 출력은 다소 충격일수도 있겠습니다. 자신의 실력이 부족했다는것은 알았는지 영어 출력에서 죄송하다고 합니다. GPT-2는 영어 데이터로 학습되었기 때문에 한국어 입력에 대해서도 영어를 출력하고, 대부분 같은 단어들을 반복하는 것을 확인 할 수 있습니다.
그럼 코드에서 사용된 각 파라미터들에 대해 알아보겠습니다.
kor_encode = tokenizer.encode(kor_inputs, max_length=1024, truncation=True, return_tensors='pt')
eng_encode = tokenizer.encode(eng_inputs, max_length=1024, truncation=True, return_tensors='pt')
max_length = 1024 -> 글자의 수를 1024토큰으로 제한합니다. 만약 그 이상으로 넘어가는 문장이 입력된다면 truncation=True -> 문장을 잘라내도록 하겠습니다.
return_tensors = ['pt', 'tf', 'np', 'jax'] 토크나이저가 반환할 객체의 클래스를 지정합니다.
pt = 파이토치 텐서
tf = 텐서플로우 객체
np = 넘파이 객체
jax = JAX 객체
kor_outputs = model.generate(kor_encode, max_length=128, pad_token_id=tokenizer.eos_token_id)
eng_outputs = model.generate(eng_encode, max_length=128, pad_token_id=tokenizer.eos_token_id)
max_length = 128 -> 모델이 생성할 토큰의 최대 개수를 제한합니다. 필자의 예시에서 입력한 문장은 100토큰 미만의 짧은 문장이기 때문에 128로 설정하였으나, 오류가 발생할 경우 1024로 설정하시면 됩니다. 대신, 그만큼 모델이 생성하는데 오랜 시간이 걸릴 수 있습니다.
pad_token_id=tokenizer.eos_token_id -> 하지 않으면
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation. 라는 오류가 발생하기 때문에 설정하였습니다.
다음 장에서는 Trainer를 이용하여 모델을 직접 학습시켜 보도록 하겠습니다.
'인공지능' 카테고리의 다른 글
| AI-hub 공공데이터를 활용하여 한국어-영어 번역 LLM 만들기 (3) GPT 학습시키기 (0) | 2024.08.19 |
|---|---|
| AI-hub 공공데이터를 활용하여 한국어-영어 번역 LLM 만들기 (1) 데이터 가공 (0) | 2024.07.09 |
| Segment Anything Model(SAM) 사용하기 (0) | 2024.07.01 |
| Tensorflow addons 을 이용한 F1 score 출력 (0) | 2022.10.14 |
| EfficientNet B0 ~ B7 input / output shape(size), params (0) | 2022.10.12 |



