드디어 GPT를 이용한 학습을 시작해보도록 하겠습니다.
시작에 앞서 필자의 컴퓨터 사양 및 라이브러리 버전에 대해 알려드리겠습니다.
CPU : i7-8700K, 3.70GHz
GPU : NVIDIA GeForce RTX 2080 Ti 11GB, 메모리 : 64GB
python==3.10
pytorch==2.1.0+cu118
이외 사용한 라이브러리는 pandas, sklearn, transformers, nltk 입니다.
nltk에서 제공하는 bleu score로 모델의 성능을 평가해보도록 하겠습니다.
import pandas as pd
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset
from transformers import GPT2Tokenizer, GPT2LMHeadModel, Seq2SeqTrainingArguments, Seq2SeqTrainer
import torch
import nltk
from nltk.translate.bleu_score import sentence_bleu
# nltk 다운로드
nltk.download('punkt')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'left'
model = GPT2LMHeadModel.from_pretrained('gpt2')
df = pd.read_csv('translation_with_llm/dataset.csv')
df = df[:100000]
먼저 gpt2 모델과 토크나이저를 불러온 후 이전에 저장해 놓았던 csv 데이터셋을 불러옵니다.
기계번역은 한국어로부터 영어를 생성 하는 작업이기 때문에 LM head가 붙어있는 GPT2LMHeadModel 클래스로 불러옵니다.
100만건의 데이터를 모두 학습해보려 했지만 생각보다 많더라구요 ;;;; 그래서 10만건으로 줄였습니다.

또한 토크나이저의 max_length를 1024로 매우 큰 파라미터를 주었더니 위 사진처럼 2694시간이 걸린다는... 실험을 위해 과감하게 줄여보도록 하겠습니다.
prefix = "translate Korean to English: "
def preprocess_function(examples):
inputs = [prefix + ex['ko'] for ex in examples]
targets = [ex['en'] for ex in examples]
model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True, padding="max_length")
return model_inputs
# DataFrame을 리스트로 변환 후 전처리 함수 적용
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42)
train_df = train_df.to_dict(orient='records')
train_df = preprocess_function(train_df)
val_df = val_df.to_dict(orient='records')
val_df = preprocess_function(val_df)
class TranslationDataset(Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __len__(self):
return len(self.encodings['input_ids'])
def __getitem__(self, idx):
return {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
train_dataset = TranslationDataset(train_df)
val_dataset = TranslationDataset(val_df)
모델에 한국어를 영어로 번역하라는 의미에서 입력으로 쓰일 한국어 문장에 prefix를 추가해줍시다.
또한 모델에 입력시키기 위한 데이터 전처리 과정 preprocess_function 을 해줍니다.
tokenizer에 입력으로 사용될 한국어 input과 목표로 하는 영어 text_targtet=targets로 지정해줍니다.
max_length=128로 지정하나, 만약 넘어갈 경우 truncation=True(자른다), 짧을 경우 padding="max_length"(max_length만큼 패딩을 추가해준다)

모델로 입력되는 샘플 데이터를 출력해보겠습니다. tokenizer 의 padding='left'로 설정하였기 때문에 좌측 텐서들이 패딩토큰이며 이후 각 단어에 알맞는 토큰들로 바뀌었습니다.
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = [pred[:list(pred).index(tokenizer.eos_token_id)] if tokenizer.eos_token_id in pred else pred for pred in predictions]
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# BLEU 점수 계산
bleu_scores = []
for pred, label in zip(decoded_preds, decoded_labels):
pred_tokens = nltk.word_tokenize(pred)
label_tokens = [nltk.word_tokenize(label)]
bleu_score = sentence_bleu(label_tokens, pred_tokens)
bleu_scores.append(bleu_score)
avg_bleu_score = sum(bleu_scores) / len(bleu_scores)
return {"bleu": avg_bleu_score}
training_args = Seq2SeqTrainingArguments(
output_dir='translation_with_llm/results',
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
num_train_epochs=3,
gradient_accumulation_steps=128,
logging_strategy='epoch',
logging_dir='translation_with_llm/logs',
do_train=True,
do_eval=True,
evaluation_strategy='epoch',
predict_with_generate=True
)
model = model.to(device)
model.generation_config.max_new_tokens = 128
# 트레이너 설정
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
모델의 bleu score를 측정하기 위한 custom metric를 정의해준 후 trainer를 훈련시켜주겠습니다.
모델 훈련에 매우 오랜시간이 걸리기 때문에 3epoch만 학습 후 결과를 보겠습니다.

훈련간에 측정된 loss와 bleu 점수가 매우 낮습니다. 실제 text를 입력해볼까요?
model.eval()
model.generation_config.pad_token_id = tokenizer.pad_token_id
sample_text = '내일 아침 수업은 최 박사님의 외부일정으로 인해 취소되었음을 알려드립니다.'
inputs = tokenizer.encode(prefix + sample_text, return_tensors='pt')
inputs = inputs.to(device)
outputs = model.generate(inputs, max_new_tokens=128, num_beams=5)
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(translated_text)
흐음... 훈련 전과 같이 똑같은 문장을 출력합니다. 왜 그럴까요?
이는 gpt2의 토크나이저를 사용해서 한국어를 제대로 토큰화 하지 못하였기 때문입니다.
다음 코드를 통해 왜 그런지 알아보겠습니다.
sample = df.iloc[0]
inputs = tokenizer(sample['ko'], text_target=sample['en'])
print(tokenizer.convert_ids_to_tokens(inputs['input_ids']))
print(tokenizer.convert_ids_to_tokens(inputs['labels']))
한국어를 토큰화 한 후 다시 문자로 변환했더니 도저히 알아볼 수 없는 문자들이 출력됩니다.
반면 영어를 토큰화 한 후 다시 문자로 변환하면

위와 같이 G' 이라는 문자를 빼고 읽을 시 It is to be announced that class... 라는 문장으로 온전히 복구된 것을 확인할 수 있습니다.
그럼 어떻게 해야할까요?
영어로만 학습된 gpt2 토크나이저가 아닌, 영어와 한국어가 같이 학습된 토크나이저를 사용하거나 새로운 토크나이저를 직접 학습시켜야 합니다.
본 포스트에서는 사전훈련된 GPT2와 GPT2의 토크나이저를 이용하기 위해 새로운 한국어 토크나이저를 훈련시켜보도록 하겠습니다.
1. 한국어 토크나이저 훈련하기
토크나이저를 훈련시키기 위해서는 가능한 많은 단어와 문장을 가진 데이터셋을 이용하는것이 좋습니다. 모집단이 커질수록 데이터의 분포와 실제 사용되는 단어들의 분포가 유사해지기 때문입니다.
토크나이저는 txt파일을 이용해 훈련이 진행되기 때문에 데이터를 불러와 txt로 변환한 후 훈련을 진행하겠습니다.
import pandas as pd
from transformers import GPT2TokenizerFast
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
df = pd.read_csv('translation_with_llm/dataset.csv')
ko_texts = df['ko'].tolist()
# 추출된 텍스트 데이터를 파일로 저장 (Tokenizer는 파일로부터 학습을 진행함)
with open('translation_with_llm/ko_texts.txt', 'w', encoding='utf-8') as f:
for line in ko_texts:
f.write(line + '\n')
# 토크나이저 훈련
tokenizer_en = GPT2TokenizerFast.from_pretrained('gpt2')
ByteLevelBPE_tokenizer_kr_vocab_size = tokenizer_en.vocab_size - 1
from tokenizers import ByteLevelBPETokenizer
ByteLevelBPE_tokenizer_kr = ByteLevelBPETokenizer()
paths = [str('translation_with_llm/ko_texts.txt')]
# Customize training with <|endoftext|> special GPT2 token
ByteLevelBPE_tokenizer_kr.train(files=paths,
vocab_size=ByteLevelBPE_tokenizer_kr_vocab_size,
min_frequency=2)
# Get sequence length max of 1024
ByteLevelBPE_tokenizer_kr.enable_truncation(max_length=1024)
def add_special_tokens(tokenizer, special_tokens):
for token_name, token in special_tokens.items():
if token not in tokenizer.get_vocab():
tokenizer.add_tokens([token])
return tokenizer
special_tokens = {'bos_token': '<|endoftext|>',
'eos_token': '<|endoftext|>',
'unk_token': '<|endoftext|>',
'pad_token': '<|endoftext|>'}
ByteLevelBPE_tokenizer_kr = add_special_tokens(ByteLevelBPE_tokenizer_kr, special_tokens)
path_to_ByteLevelBPE_tokenizer_pt_rep = 'translation_with_llm'
ByteLevelBPE_tokenizer_kr.save_model(str(path_to_ByteLevelBPE_tokenizer_pt_rep))
사전훈련된 GPT2 토크나이저의 special tokens들은 모두 <|endoftext|> 토큰으로 되어 있었기 때문에 같은 설정으로 변환해준 후 토크나이저를 훈련시킨다음 저장합니다.
ByteLevelBPE_tokenizer_kr.save_model(...)을 통해 저장한 토크나이저를 불러와 잘 작동하는지 확인해봅시다.
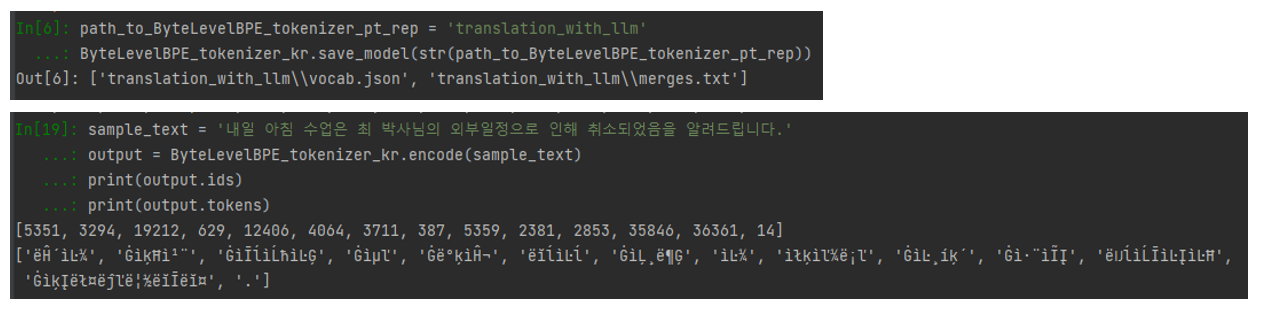
한국어가 토큰 id로 잘 변환이 되지만 ByteLevel의 토크나이저이기 때문에 알아듣기 어려운 문자들로 변환됩니다.

하지만 다시 text로 변환하였을 때 정상적으로 변환되는것을 확인할 수 있습니다.
2. GPT 훈련시키기
import pandas as pd
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset
from transformers import GPT2TokenizerFast, GPT2LMHeadModel, Seq2SeqTrainingArguments, Seq2SeqTrainer
import torch
import nltk
from nltk.translate.bleu_score import sentence_bleu
# nltk 다운로드
nltk.download('punkt')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 영어로 사전훈련된 토크나이저 불러오기
tokenizer_en = GPT2TokenizerFast.from_pretrained('gpt2')
tokenizer_en.pad_token = tokenizer_en.eos_token
# 한국어로 사전훈련된 토크나이저 불러오기
tokenizer_kr = GPT2TokenizerFast.from_pretrained('translation_with_llm')
tokenizer_kr.add_special_tokens({'pad_token': '<|endoftext|>'})
tokenizer_kr.model_max_length = 128
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 데이터 불러오기
df = pd.read_csv('translation_with_llm/dataset.csv')
df = df[:100000]
한국어에서 영어로 번역하기 위한 GPT이기 때문에 영어, 한국어 토크나이저를 모두 불러온 후 데이터를 로드해줍니다.
prefix = "한국어를 영어로 번역 : "
class TranslationDataset(Dataset):
def __init__(self, corpus, ko_tokenizer, en_tokenizer):
self.ko_texts = [prefix + ex for ex in corpus['ko']]
self.en_texts = [ex for ex in corpus['en']]
self.ko_tokenizer = ko_tokenizer
self.en_tokenizer = en_tokenizer
def __len__(self):
return len(self.ko_texts)
def __getitem__(self, idx):
ko_text = self.ko_texts[idx]
en_text = self.en_texts[idx]
ko_encodings = tokenizer_kr(ko_text, truncation=True, padding='max_length', max_length=128)
en_encodings = tokenizer_en(en_text, truncation=True, padding='max_length', max_length=128)
return {
'input_ids': ko_encodings.data['input_ids'],
'attention_mask': ko_encodings.data['attention_mask'],
'labels': en_encodings.data['input_ids']
}
# DataFrame을 리스트로 변환 후 전처리 함수 적용
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42)
train_dataset = TranslationDataset(train_df, tokenizer_kr, tokenizer_en)
val_dataset = TranslationDataset(val_df, tokenizer_kr, tokenizer_en)
GPT에게 한국어에서 영어로 번역하라는 task를 인식시키기 위해 prefix를 설정하고 한국어 문장을 encoding 한 input_ids, attention_mask와 target으로 지정할 영어 문장을 encoding 한 후의 label을 반환해주는 Dataset을 선언해줍니다.
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = [pred[:list(pred).index(tokenizer_en.eos_token_id)] if tokenizer_en.eos_token_id in pred else pred for pred in predictions]
decoded_preds = tokenizer_en.batch_decode(predictions, skip_special_tokens=True)
decoded_labels = tokenizer_en.batch_decode(labels, skip_special_tokens=True)
# BLEU 점수 계산
bleu_scores = []
for pred, label in zip(decoded_preds, decoded_labels):
pred_tokens = nltk.word_tokenize(pred)
label_tokens = [nltk.word_tokenize(label)]
bleu_score = sentence_bleu(label_tokens, pred_tokens)
bleu_scores.append(bleu_score)
avg_bleu_score = sum(bleu_scores) / len(bleu_scores)
return {"bleu": avg_bleu_score}
training_args = Seq2SeqTrainingArguments(
output_dir='translation_with_llm/results',
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
num_train_epochs=5,
gradient_accumulation_steps=128,
logging_strategy='epoch',
logging_dir='translation_with_llm/logs',
do_train=True,
do_eval=True,
evaluation_strategy='epoch',
predict_with_generate=True
)
model = model.to(device)
model.config.pad_token_id = tokenizer_en.pad_token_id if tokenizer_en.pad_token_id is not None else 0
model.generation_config.max_new_tokens = 128
# 트레이너 설정
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics
)
trainer.train()
모델의 성능을 측정할 metric 클래스를 선언해준 후 위 코드를 이용해 모델을 학습시킵니다. 이번에는 5번정도의 epoch을 주도록 하겠습니다.

bleu score가 비정상적으로 낮게 측정이 되었습니다.
예시 문장을 이용해 번역이 되는지 확인해보겠습니다.
def translate(ko_sentence):
model.eval()
inputs = tokenizer_kr.encode(prefix + ko_sentence, return_tensors='pt')
inputs = inputs.to(device)
outputs = model.generate(inputs, max_length=128, num_beams=5, early_stopping=True)
translated_text = tokenizer_en.decode(outputs[0], skip_special_tokens=True)
return translated_text
sample_text = '내일 아침 수업은 최 박사님의 외부일정으로 인해 취소되었음을 알려드립니다.'
translated_sentence = translate(sample_text)
print(translated_sentence)
흠.... 10만건의 데이터로는 학습이 부족했던 탓일까요. 아니면 훈련 방식이 잘못된 것인지 ... 이상으로 마무리하도록 하겠습니다.
'인공지능' 카테고리의 다른 글
| AI-hub 공공데이터를 활용하여 한국어-영어 번역 LLM 만들기 (2) 모델 불러오기 (0) | 2024.07.11 |
|---|---|
| AI-hub 공공데이터를 활용하여 한국어-영어 번역 LLM 만들기 (1) 데이터 가공 (0) | 2024.07.09 |
| Segment Anything Model(SAM) 사용하기 (0) | 2024.07.01 |
| Tensorflow addons 을 이용한 F1 score 출력 (0) | 2022.10.14 |
| EfficientNet B0 ~ B7 input / output shape(size), params (0) | 2022.10.12 |



